Weft QDA
Weft QDA is/was a free, open-source package for the analysis of qualitative (unstructured text) data. I originally wrote it in 2003-2004 to analyse interviews and field notes from my MSc dissertation research on credit unions in South London.
The Software
It implemented a simple ‘code and retrieve’ approach - first, text documents are imported, then read through. Whilst reading, sections of text are marked as being associated with one or more categories or concepts. The precise type of association between text and category depends on the type of analysis being performed; it isn’t specified by the software. Coding a document looked like this in Weft QDA:
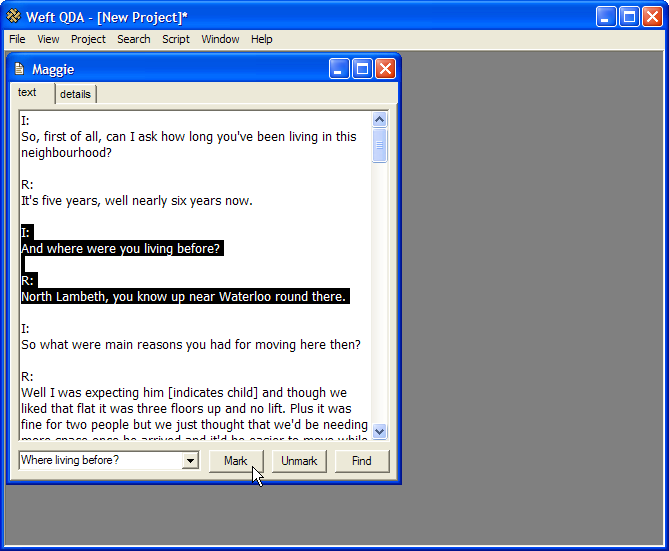
The software then allows all the textual extracts associated with a particular category to be viewed side-by-side, and for further categories then to be applied. The analytic categories can thus be refined and developed, although again, the particular method of further reading and analytic development isn’t prescribed by Weft QDA. Reviewing and coding a category looked like this:
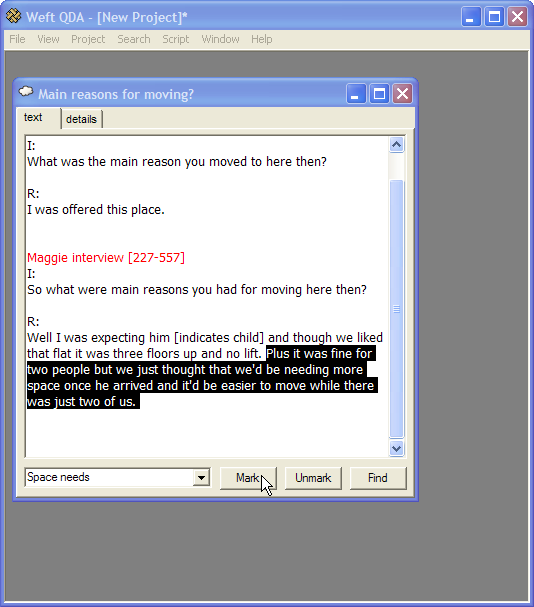
Weft QDA also allowed some further techniques for exploring the imported and coded data, such as free-text searches and identifying passages of text coded by combinations of categories.
Background
After I finished the dissertation, I tidied up the software and released it on the internet in 2005. Altogether RubyForge, where the downloads are hosted, counts some 80,000 downloads of the software, and it has been used in some ‘real’ projects.
The motivation was firstly, simply expense - the commercial software packages are (for a typical student’s budget, if not for a well-funded university) not cheap. The second motivation was simplicity; as Anne Lewins put it several years ago, the Market leading software packagesn reach the parts where no-one wants to go. In other words, they tended to develop increasingly baroque and obscure features ino order to differentiate themselvse and justify their cost, when for many users a minimal set of features (basically, code/retrieve/search) was sufficient.
Weft QDA and Open Source
Although found the software useful and contributed to it by suggestions and so on, it didn’t thrive as an open-source project in the sense of receiving contributions to its improvement. As happens to other projects, my own research interests changed. From around 2007/08 I gave up plans to maintain or further develop the software.
There are plenty of scientific, research and academic open-source projects that do succeed in developing a body of developers that allow them to become self-sustaining - R Statistics being an obvious one. I haven’t followed what has happened in open-source qualitative data analysis for several years, but in a talk in 2008 fairly pessimistic, for several reasons:
- Unlike in more mathematically oriented disciplines, those who are potential users of the software are unlikely to have elsewhere developed skills in programming (as a set of tools, types of reasoning, procedures and so on)
- Within academic careers, developing software and similar research tools as an activity itself is relatively unrewarded by career advancement and hard to fund.
- Unlike, for example, the implementation of new statistical models in R, or novel software processing physical data, free and generic software is unlikely to be methodologically novel or provide publishable results that could not otherwise be produced.
Semi-archived Weft QDA information and downloads here: http://www.pressure.to/qda